
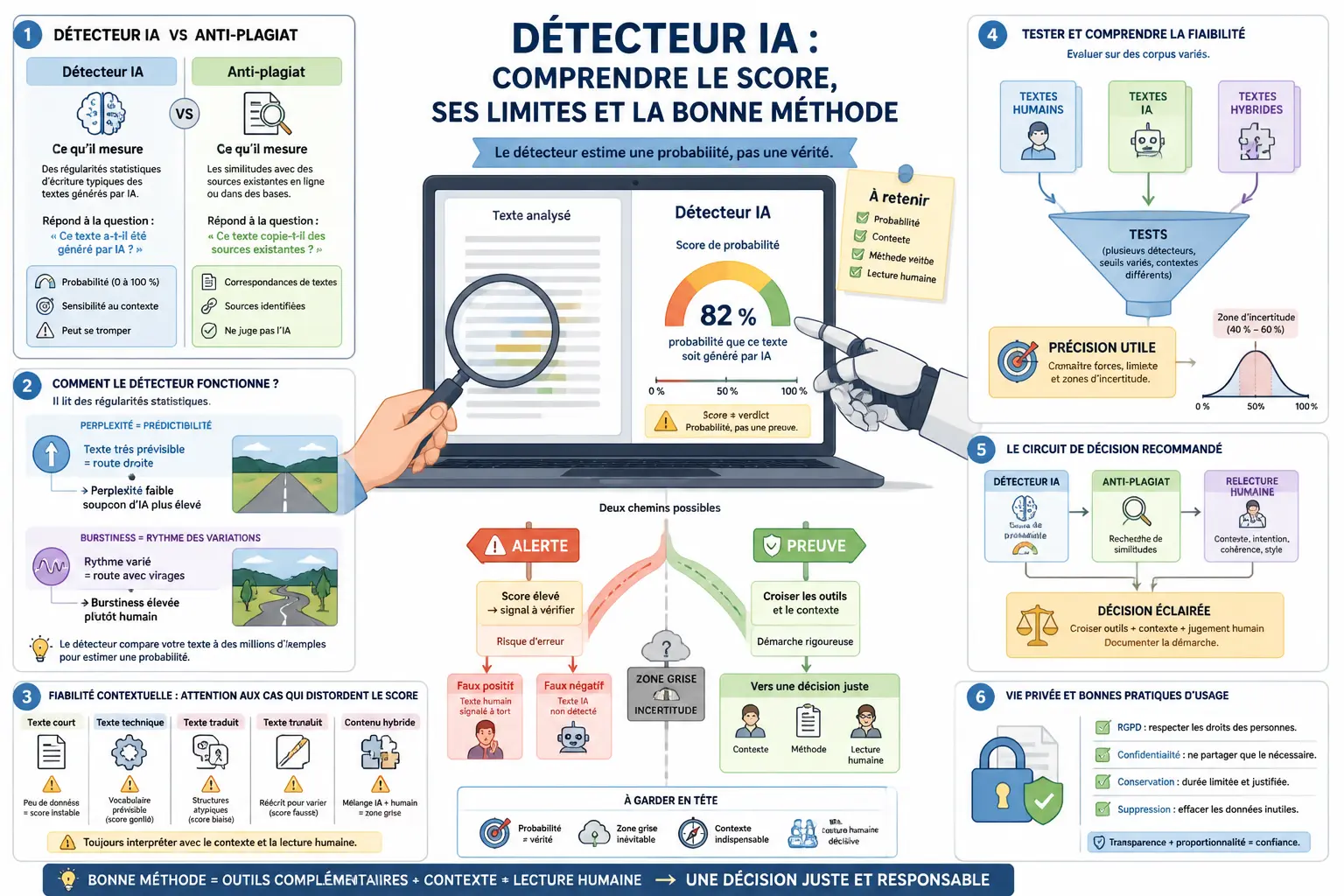
- Un detecteur ia estime une probabilité, mais ne prouve jamais seul l’origine d’un texte.
- Le score sert surtout à prioriser une relecture, pas à rendre un verdict automatique.
- La détection d’IA et l’anti-plagiat mesurent des choses différentes et doivent être combinés.
- Les textes courts, techniques, traduits ou humanisés faussent souvent les résultats.
- En 2026, la fiabilité dépend du contexte, de la langue, du format et de la méthode de test.
- Pour décider juste, croisez détecteur IA, anti-plagiat et relecture humaine.
Quand un outil affiche 87 % sur un texte, beaucoup s’arrêtent là. Mauvais réflexe. Un détecteur IA ne reconnaît pas un auteur, il estime une probabilité à partir de signaux statistiques, un peu comme on lit une courbe de trésorerie avant de décider si le mois va passer ou coincer.
En 2026, le sujet n’est pas seulement de savoir si un texte « vient de l’IA », mais de comprendre ce que le score prouve, ce qu’il suggère et ce qu’il ne tranche pas. C’est là que la lecture devient utile, et qu’elle évite bien des décisions trop rapides.
Détecteur IA : à quoi sert-il vraiment, et ce qu’il ne peut pas prouver seul
Un détecteur de contenu IA sert d’abord à trier, alerter et prioriser. Il aide à repérer un texte généré par l’IA, un contenu hybride ou une rédaction très lisse, puis à déclencher une vérification plus sérieuse.
En revanche, il ne suffit pas à sanctionner un texte, ni à certifier qu’il a été écrit par un humain. Le score donne une direction, pas une preuve.
Un score n’est pas un verdict
Vous collez un texte. L’outil affiche 82 %. La vraie question n’est pas « vrai ou faux ? », mais 82 % de quoi, sur quel corpus, avec quelle marge d’erreur ? C’est là que beaucoup se trompent.
Un score élevé peut simplement dire que le texte ressemble à ce que le modèle a appris comme « typique » d’un contenu généré par l’IA. Autrement dit, le signal est utile, mais il reste une estimation.
Le mécanisme est simple. Le logiciel compare des régularités d’écriture, puis en déduit un résultat de détection. Si vous utilisez ce score pour décider seul, vous mélangez alerte et preuve. Honnêtement, ce n’est pas la même chose.
Dans la pratique, le score sert à prioriser une relecture. Un 20 % n’appelle pas le même niveau d’attention qu’un 90 %. Mais entre les deux, il y a souvent un terrain gris, surtout si le texte a été relu, raccourci, traduit ou humanisé.
Détection d’IA et anti-plagiat ne regardent pas la même chose
L’anti-plagiat compare des ressemblances avec des sources existantes. La détection d’IA, elle, cherche à comprendre si l’écriture ressemble à celle d’un modèle génératif, même si le texte est original.
On ne regarde pas le même tuyau. L’un mesure la fuite de copie, l’autre la probabilité de génération. Les deux approches répondent à des questions différentes.
C’est pour cela qu’un texte peut être original mais signalé comme IA, ou à l’inverse très proche d’une source sans déclencher un détecteur d’IA. Pour un contrôle sérieux, surtout en contexte académique, éditorial ou RH, les deux outils se complètent.
Le bon réflexe, c’est de combiner selon le risque. Un article de blog peu sensible ne demande pas la même profondeur qu’un mémoire, une note de recrutement ou un document de conformité. Votre cadre de décision change avec l’enjeu.
Ce que l’outil analyse derrière l’écran
Derrière l’interface, le modèle de détection ne cherche pas une signature magique. Il observe des motifs d’écriture, des répétitions, des structures trop régulières et des indices statistiques qui ressemblent à du texte généré par l’IA.
La technologie de détection avance, mais elle travaille avec des probabilités, pas avec une certitude absolue. C’est précisément ce qui impose de rester prudent au moment d’interpréter le résultat.
Le logiciel cherche des régularités, pas une signature magique
Les signaux les plus courants sont assez simples à lire. Le texte paraît trop uniforme, les phrases se suivent avec une logique trop propre, le vocabulaire varie peu, et les transitions sont lisses comme un calendrier sans imprévu.
On parle parfois de perplexité et de burstiness. En langage simple, la perplexité mesure à quel point le texte est prévisible. La burstiness regarde si les phrases alternent naturellement entre blocs courts, phrases plus denses et ruptures de rythme.
Un texte humain a souvent des petites irrégularités. Un texte IA peut paraître trop bien rangé. C’est aussi pour cela que certains détecteurs se trompent sur des textes très rédigés, très propres ou très normés.
Les modèles évoluent, la détection court derrière
Le saviez-vous ? Les détecteurs d’IA ne suivent jamais parfaitement les versions successives de ChatGPT, GPT-4, GPT-5, Gemini, Claude, Mistral, Copilot, Grok ou DeepSeek. Chaque génération change un peu la manière de produire du texte.
Chaque réécriture humaine brouille encore davantage les pistes. Plus les modèles génératifs progressent, plus la frontière devient floue. Un prompt long, une reformulation, une traduction ou une humanisation du texte peuvent suffire à déplacer le score de détection.
Du coup, un outil peut reconnaître un contenu IA aujourd’hui et le manquer demain sur une version légèrement différente. C’est pour cela qu’il faut parler de fiabilité contextuelle plutôt que de vérité universelle.
Un détecteur peut être cohérent sur un certain type de contenu, puis moins bon sur d’autres. Le modèle de détection n’est pas figé. Il suit, avec retard.
Le français et les textes courts brouillent les pistes
Beaucoup d’outils sont pensés d’abord pour l’anglais. En français, les résultats bougent davantage, surtout sur les textes techniques, les contenus juridiques, les fiches produit ou les notices administratives.
Vous avez peut-être déjà vu un paragraphe banal ressortir comme « suspect ». C’est un faux positif classique. Le problème se renforce quand le texte est court.
En dessous de 200 ou 300 mots, le détecteur d’IA a peu de matière pour établir une lecture stable. Ajoutez un jargon métier, une traduction ou une relecture poussée, et le résultat de détection devient plus fragile.
| Situation | Effet sur le score | Risque principal |
|---|---|---|
| Texte court | Score instable | Faux négatif ou faux positif |
| Texte technique | Style standardisé | Faux positif |
| Texte traduit | Rythme perturbé | Score trompeur |
| Texte humanisé | Signal brouillé | Baisse de fiabilité |
| Contenu hybride | Mélange de signaux | Lecture ambiguë |
Un score de détection repose aussi sur des signaux difficiles à matérialiser clairement, comme l’explique notre page sur la notion d’intangible en entreprise.
Utiliser un vérificateur sans se faire piéger par l’interface
Sur l’écran, tout semble simple. Collage du texte, lancement de l’analyse, rapport généré, phrases surlignées, pourcentage de contenu IA. Mais le piège est là : l’interface donne l’illusion d’un verdict net, alors qu’elle ne produit qu’une estimation de détection.
On part du symptôme visible, puis on remonte au mécanisme avant de décider. C’est souvent ce détour qui évite les erreurs d’interprétation.
Commencez par le bon format et un échantillon suffisant
Le parcours classique est toujours le même. Vous collez un texte ou vous importez un document, vous lancez l’analyse, puis vous récupérez un score global avec des passages surlignés.
Certains outils proposent aussi le téléchargement de fichiers, l’analyse par lot, ou une version sans inscription pour tester vite. Avant d’interpréter le moindre résultat, vérifiez trois choses : la longueur du texte, la langue utilisée et la version du document analysée.
Un brouillon, une version corrigée ou un texte tronqué ne donnent pas le même signal. Votre TVA sort quand, exactement ? Pour un texte, c’est pareil : le contexte compte.
Le rapport se lit phrase par phrase, pas seulement en pourcentage
Un score global de 40 %, 70 % ou 95 % ne raconte pas la même histoire. Mais ce pourcentage ne suffit jamais à lui seul. Il faut regarder les phrases surlignées, la cohérence des blocs, le niveau de confiance, et parfois la répartition entre texte humain et contenu généré par l’IA.
Un texte peut afficher un score moyen et contenir deux paragraphes très suspects. À l’inverse, un score élevé peut venir d’un style administratif très lisse, sans que le contenu soit réellement produit par une IA. C’est là que la lecture humaine reprend la main.
| Indicateur | Ce qu’il dit | Ce qu’il ne dit pas |
|---|---|---|
| Score global | Probabilité estimée | Preuve d’origine |
| Phrases surlignées | Zones à relire | Auteur réel |
| Niveau de confiance | Solidité interne | Vérité absolue |
| Répartition humain / IA | Mélange probable | Histoire complète |
| Rapport généré | Synthèse utile | Décision finale |
Certains textes font grimper le score pour de mauvaises raisons
Les cas ambigus sont connus. Texte court, résumé, contenu corrigé par un humain, texte traduit, consignes répétitives, note technique, fiche produit, document administratif, tout cela peut fausser la lecture.
Un détecteur IA n’aime pas toujours les écritures propres, très cadrées, très régulières. Quand le score vous surprend, revenez à la source.
Comparez la version initiale et la version éditée. Croisez avec l’historique de production, les outils utilisés, les délais et les personnes qui ont réellement retravaillé le texte. Vous voulez savoir si c’est du contenu écrit par un humain ? Alors regardez aussi la trace du travail, pas seulement la sortie finale.
Précision réelle en 2026 : ce que disent des tests transparents
La question utile n’est pas « cet outil affiche-t-il 99 % ? », mais dans quelles conditions se trompe-t-il ? En 2026, la variance reste le sujet central.
Selon le prompt, la longueur du texte ou une simple réécriture, le score peut monter ou descendre franchement. C’est cette instabilité qu’il faut mesurer.
Un benchmark crédible part d’exemples français et d’une méthode visible
Un test sérieux compare plusieurs corpus. D’un côté, des textes humains. De l’autre, des textes générés par l’IA. Entre les deux, des contenus hybrides, relus, raccourcis, paraphrasés ou traduits.
Tout cela doit être testé sur plusieurs longueurs, avec les mêmes consignes. Les familles d’exemples utiles sont concrètes : article de blog, devoir d’étudiant, fiche produit, courriel commercial, note technique, traduction, texte paraphrasé, texte relu par un humain.
Sans méthode visible, le « meilleur détecteur IA » ne veut pas dire grand-chose. Avec une méthode, on parle enfin de précision utile.
| Élément de test | Pourquoi c’est utile | Ce qu’il faut publier |
|---|---|---|
| Corpus humain | Mesurer les faux positifs | Exemples et taux d’erreur |
| Corpus IA | Mesurer les faux négatifs | Seuil retenu |
| Textes hybrides | Tester les zones grises | Cas limites |
| Textes courts et longs | Vérifier la stabilité | Variance par longueur |
| Plusieurs domaines | Révéler les biais | Limites observées |
Pour décider juste, combinez l’outil, l’anti-plagiat et la relecture humaine
La bonne méthode ressemble à un circuit de décision simple. Le détecteur IA sert d’alerte. L’anti-plagiat mesure la similarité. La relecture humaine tranche sur le contexte, les incohérences et la traçabilité.
On ne demande pas à un seul outil de faire les trois métiers. Le niveau de contrôle dépend du risque. Faible enjeu, simple vérification. Enjeu moyen, second outil. Enjeu fort, double contrôle, relecture et demande de preuves de rédaction si nécessaire.
Une fois ce décalage posé entre promesse marketing et risque d’erreur, on voit où ça se rattrape : sur la méthode, sur les seuils ou sur la décision finale. C’est souvent là que la qualité du contrôle se joue vraiment.
Face à un pourcentage affiché avec assurance, il aide de raisonner comme avec l’indice Syntec Insee et son mode d’utilisation : méthode, source et limites comptent autant que la valeur.
Faire le bon choix selon vos usages
Tous les détecteurs d’IA ne servent pas le même usage. Un étudiant ne cherche pas la même chose qu’un enseignant, une agence, un média, un recruteur ou une équipe contenu.
Le bon outil, c’est celui qui colle à votre volume, à votre niveau de risque et à vos données. Un comparatif utile regarde le gratuit ou premium, les limites de mots, la prise en charge de plusieurs langues, l’analyse de documents, les fichiers par lot, l’export du rapport et, parfois, l’intégration via interface de programmation.
Certains outils annoncent un support multilingue. Vérifiez quand même les langues prises en charge en français, car c’est souvent là que les écarts apparaissent.
| Critère | Question à se poser |
|---|---|
| Volume | Combien de textes par semaine ? |
| Enjeu | Simple tri ou décision sensible ? |
| Formats | Texte collé, documents, fichiers par lot ? |
| Langues | Français seul ou support multilingue ? |
| Rapport | Score seul ou analyse détaillée ? |
| Données | Conservation, suppression, conformité au RGPD ? |
La confidentialité des données mérite aussi un vrai regard. Où les textes sont-ils hébergés ? Sont-ils conservés ? Servent-ils à l’entraînement du modèle ? Y a-t-il un accord de traitement des données, une suppression manuelle, une journalisation ?
Pour un cabinet, une agence ou un service RH, la question n’est pas secondaire. Elle pèse parfois autant que la précision affichée.
Un dernier point. Si vous traitez des contenus sensibles, regardez aussi le cadre RGPD et les documents contractuels proposés par l’éditeur. C’est souvent moins vendeur qu’un score à 98 %, mais beaucoup plus utile quand il faut justifier un choix.
Le sujet se résume assez bien : un détecteur d’IA est un outil d’orientation, pas une machine à dire le vrai. Quand vous regardez le score, la langue, le contexte, la longueur et la méthode de test, vous obtenez une lecture beaucoup plus fiable.
C’est là que la décision devient propre. Pas avant. Quand votre compte de résultat semble bon mais que le solde varie selon les jours, vous cherchez le décalage. Pour le contenu, c’est pareil. Cherchez le délai, la trace, le contexte, puis arbitrez avec méthode.
Si votre compte de résultat est correct mais que le solde bancaire fait le yo-yo, le problème n’est souvent pas la rentabilité : c’est le calendrier.
Quand vous accordez 45 jours de paiement à un client, vous financez sa facture pendant 45 jours : la vente augmente le chiffre d’affaires tout de suite, mais la trésorerie n’entre qu’à l’échéance, tandis que vos charges (salaires, fournisseurs, TVA) sortent selon leur propre calendrier.
Une fois ce décalage posé, on peut regarder où ça se rattrape : sur les délais clients, sur les stocks ou sur la façon dont vous planifiez les décaissements.
Foire aux questions
Un détecteur IA peut-il prouver qu’un texte a été écrit par une IA ?
Non, un détecteur IA ne fournit pas une preuve d’origine. Il calcule une probabilité à partir d’indices stylistiques et statistiques, puis propose un score. Pour conclure, il faut toujours croiser ce résultat avec le contexte, la longueur du texte et, si possible, une relecture humaine.
Pourquoi un texte humain peut-il ressortir comme généré par l’IA ?
C’est souvent lié à un style trop régulier, à un vocabulaire très standardisé ou à un texte court. Les contenus techniques, juridiques, traduits ou fortement relus produisent aussi des faux positifs. Le détecteur IA confond alors une écriture lisse avec un contenu généré.
Quelle différence entre un détecteur IA et un anti-plagiat ?
L’anti-plagiat cherche des ressemblances avec des sources déjà publiées, alors que le détecteur IA évalue la probabilité d’une génération automatique. Un texte peut être original et tout de même suspecté par un détecteur IA. À l’inverse, un texte copié peut passer sous le radar s’il ne présente pas de signaux typiques de génération.
Le score d’un détecteur IA est-il fiable sur un texte en français ?
La fiabilité varie davantage qu’en anglais, surtout sur des contenus courts ou très spécialisés. Certains outils restent performants, mais la marge d’erreur peut augmenter selon la langue, le domaine et le niveau de réécriture. En français, mieux vaut lire le rapport comme une alerte, pas comme un verdict.
Comment utiliser un détecteur IA sans se tromper sur le résultat ?
Le bon réflexe consiste à analyser un texte suffisamment long, puis à regarder les passages signalés plutôt que le pourcentage seul. Si le score semble surprenant, comparez la version source, la version corrigée et le contexte de production. C’est souvent là que se trouve l’explication, pas dans le chiffre affiché.